Het analyseren van Amerikaanse babynamen
Op deze pagina leer je meer over de visualisatie van grote datasets.
Hoe werkt het als je gegevens gaat analyseren die uit miljoenen stukjes informatie bestaan, in plaats van een paar honderd? Grote datasets bieden uitdagingen en kansen voor het ontdekken van nieuwe informatie.
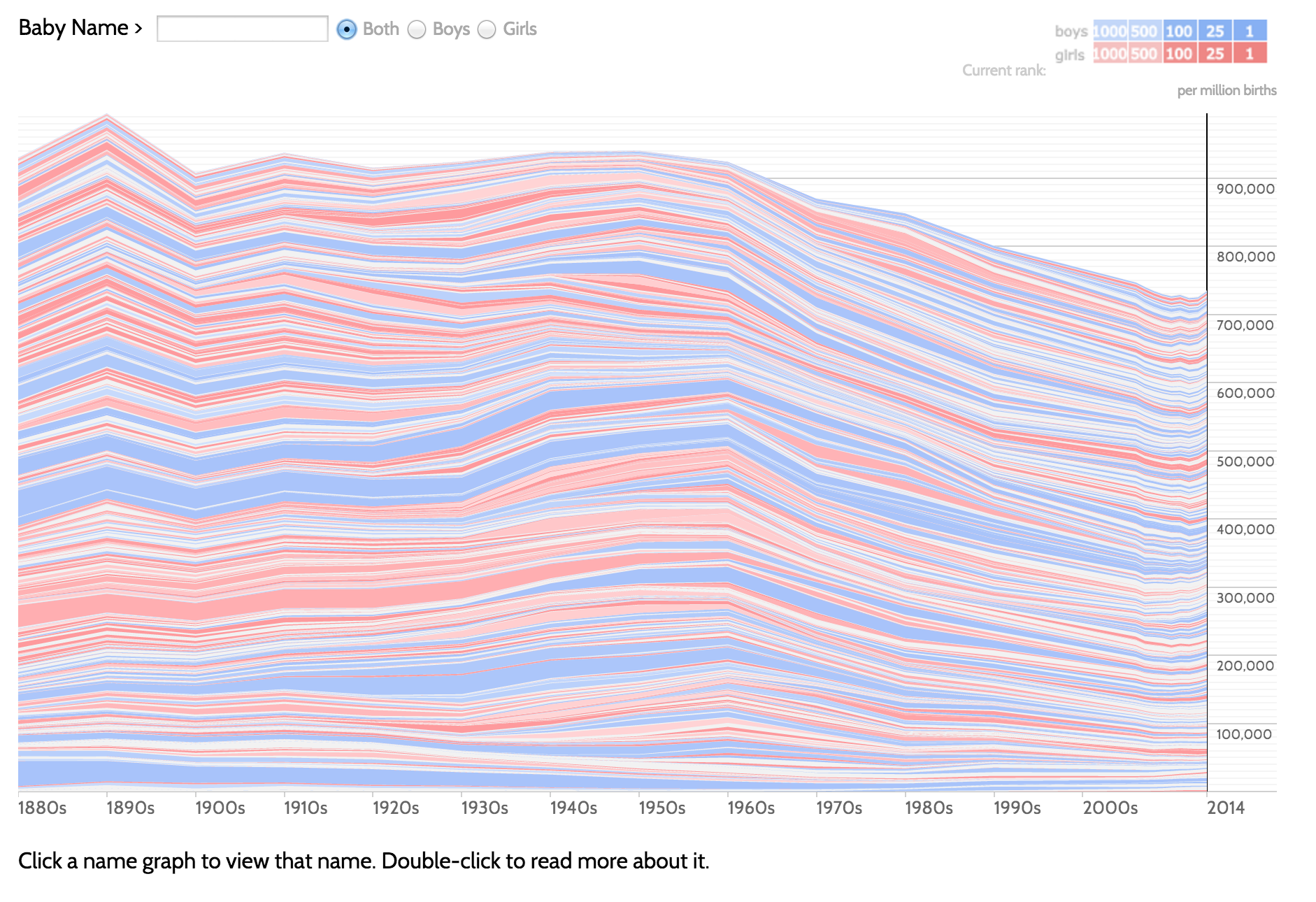
- Open deze webarchive-link: Baby Name Voyager. Het is een visualisatie van de duizend meest populaire jongens- en meisjesnamen van kinderen geboren in de Verenigde Staten tussen 1880 en 2014.
- Wat was de populairste meisjesnaam in de jaren 1900? En in de jaren 1960?
- Welke jongensnamen zijn tegenwoordig veel minder populair dan in 1880?
- Zoek op welke namen in Nederland tegenwoordig populair zijn via svb.nl 2023. Zijn hier Amerikaanse namen bij? Uit welke tijd?
- Wat kun je nog meer vinden? Zoek wat interessante details in de data en bereid je voor om het aan je klas te laten zien.
- Had je moeite bij het beantwoorden van een van bovenstaande vragen? Wat is er eventueel niet zo duidelijk aan deze visualisatie? Hoe zou je dat kunnen verbeteren?
De Baby Name Voyager is een indrukwekkende visualisatie van een grote dataset. Deze gegevens zijn afkomstig van de Social Security Administration, via een tekstbestand voor elk jaar van 1880 tot 2014. Maar het bekijken van de gegevens in zo'n plat tekstbestand zou je niet bepaald veel inzicht geven...
Grote datasets bieden unieke uitdagingen en kansen:
- Grote datasets kunnen complex of bijna onhandelbaar zijn. Het opslaan, verwerken en bewerken van grote datasets is moeilijk.
- Vanwege hun omvang en complexiteit kunnen grote datasets moeilijk te analyseren zijn. Voor zulke analyses heb je vaak veel rekenkracht nodig, die toegang geeft tot trends of verbanden die anders niet zichtbaar zouden zijn.
- Heel complexe berekeningen kunnen ook met crowdsourcing gedaan worden. Hierbij stellen mensen de rekenkracht van hun computers ter gebruik, waarbij een hele grote datasets geanalyseerd wordt door talloze computers tegelijkertijd. Voorbeelden hiervan zijn SETI @ Home en Folding @ Home. Bij SETI wordt er gezocht naar een patroon in achtergrondstraling uit het universum. Het doel is het ontdekken van een teken van buitenaards leven.
- Een aantal datasets worden gemaakt door samenwerking met andere mensen, die voegen bijvoorbeeld
afbeeldingen of video's toe.
Wikipedia, YouTube en Twitter/X zijn voorbeelden van grote datasets. Lijsten met trends worden gegenereerd door te kijken naar een dataset met alle berichten of zoekopdrachten van een bepaalde periode.
- Een gezamenlijke analyse is vaak heel handig als je met grote datasets werkt, hierdoor kan je vaak resultaten krijgen die je niet had gevonden als je in je eentje had gewerkt.
- Werken met grote datasets betekent vaak dat je nieuwe verbindingen zoekt tussen tussen de datapunten en dat je onderzoek doet naar trends binnen de dataset.
- Grote datasets bevatten vaak persoonlijke informatie zoals namen, adressen en wachtwoorden. Hierdoor kan het moeilijk zijn die data te analyseren en tegelijkertijd de persoonlijke privacy te respecteren.
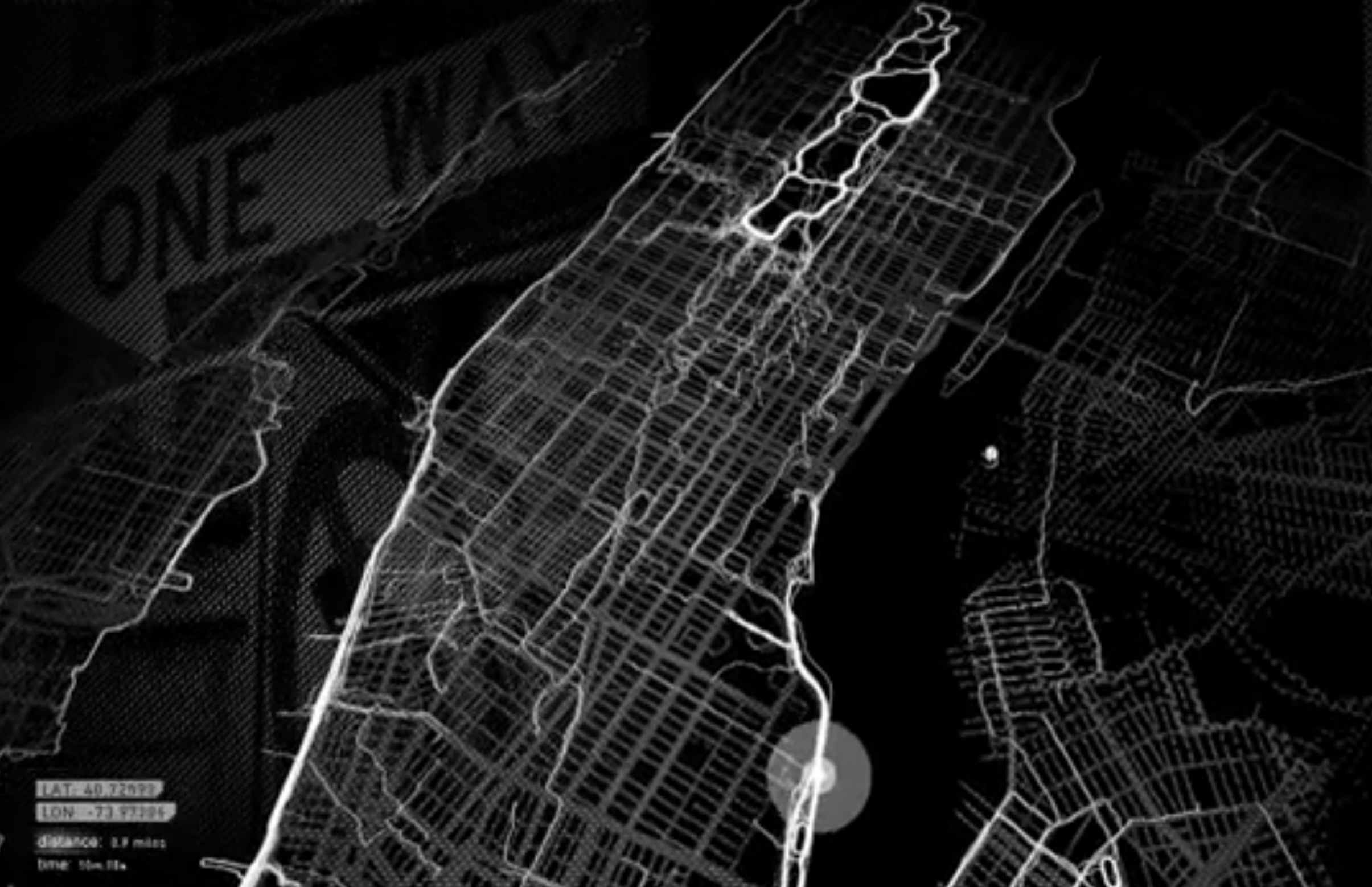 Als je grote datasets bekijkt zijn visuele en interactieve applicaties erg waardevol. Zonder deze applicaties kunnen grote datasets onbegrijpelijk zijn. In het plaatje rechts wordt YesYesNo - Nike+ City Runs
Als je grote datasets bekijkt zijn visuele en interactieve applicaties erg waardevol. Zonder deze applicaties kunnen grote datasets onbegrijpelijk zijn. In het plaatje rechts wordt YesYesNo - Nike+ City Runs
gebruikt om de paden van hardlopers in kaart te brengen (inlog bij Vimeo vereist).
- Met data van ons eigen CBS kun je zelf een data-analyse maken van de geboortes in ons land per jaar. Je kunt de data hier downloaden.
- Denk eens aan een grote dataset die je zelf hebt gemaakt en probeer deze visueel te maken met
Snap!
Let op, grote datasets kunnen teksten, geluiden, plaatjes en video’s bevatten.